
前言
题单LeetCode 热题 100的多维动态规划部分,给出解析。
62. Unique Paths
题目描述
There is a robot on an m x n grid. The robot is initially located at the top-left corner (i.e., grid[0][0]). The robot tries to move to the bottom-right corner (i.e., grid[m - 1][n - 1]). The robot can only move either down or right at any point in time.
Given the two integers m and n, return the number of possible unique paths that the robot can take to reach the bottom-right corner.
The test cases are generated so that the answer will be less than or equal to 2 * 10^9.
Example 1:
1 | Input: m = 3, n = 7 |
Example 2:
1 | Input: m = 3, n = 2 |
Constraints:
1 <= m, n <= 100
解题方法
这是一个经典的动态规划问题,要求计算从左上角到右下角的唯一路径数。机器人每次只能向右或向下移动,所以我们可以使用动态规划来解决这个问题。
思路:
- 设
dp[i][j]表示从起点(0, 0)到达位置(i, j)的唯一路径数。 - 我们可以推导出,只有从左边的格子
(i, j-1)或上面的格子(i-1, j)移动到(i, j),所以状态转移方程为:$$dp[i][j]=dp[i−1][j]+dp[i][j−1]dp[i][j] = dp[i-1][j] + dp[i][j-1]dp[i][j]=dp[i−1][j]+dp[i][j−1]$$ - 初始条件是:对于第一行和第一列,因为机器人只能一直向右或一直向下走,所以路径数都为1:
dp[0][j] = 1(第一行每个格子只能从左边来)dp[i][0] = 1(第一列每个格子只能从上面来)
- 最后返回
dp[m-1][n-1],即为到达右下角的路径数。
为了优化空间复杂度,我们可以使用空间压缩的技巧。因为在动态规划中,每次计算 dp[i][j] 只依赖于 dp[i-1][j](当前列的上方)和 dp[i][j-1](当前列的左方),因此我们可以只用一个一维数组来存储每一列的状态,反复更新这一列中的值,而不需要使用一个完整的二维数组。
优化思路:
- 使用一维数组
dp来保存当前行的路径数。 - 对于每个位置
(i, j),更新dp[j]的值为dp[j] + dp[j-1],其中dp[j]是上一行相同列的值,而dp[j-1]是当前行左边的值。
代码实现
1 | class Solution: |
优化空间复杂度:
1 | def uniquePaths(m: int, n: int) -> int: |
复杂度分析
时间复杂度:$O(m×n)$,因为我们仍然需要遍历每一个格子。
空间复杂度:$O(m×n)$ 到 $O(n)$,只需要存储当前行的路径数。
64. Minimum Path Sum
题目描述
Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right, which minimizes the sum of all numbers along its path.
Note: You can only move either down or right at any point in time.
Example 1:
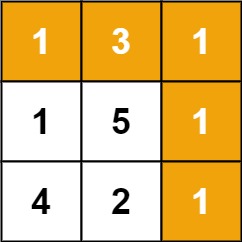
1 | Input: grid = [[1,3,1],[1,5,1],[4,2,1]] |
Example 2:
1 | Input: grid = [[1,2,3],[4,5,6]] |
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 200
解题方法
要解决这个问题,我们可以使用动态规划 (Dynamic Programming, DP) 来计算最小路径和。
思路:
- 设
dp[i][j]表示到达坐标(i, j)时的最小路径和。 - 初始条件:
dp[0][0] = grid[0][0],表示从起点到起点的路径和就是起点的值。 - 递推关系:
- 对于第一行的格子,只能从左边过来,因此有:
dp[0][j] = dp[0][j-1] + grid[0][j]。 - 对于第一列的格子,只能从上边过来,因此有:
dp[i][0] = dp[i-1][0] + grid[i][0]。 - 对于其它格子,可以从左边或者上边到达,因此有:
dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]。
- 对于第一行的格子,只能从左边过来,因此有:
- 最终,
dp[m-1][n-1]就是从左上角到右下角的最小路径和。
为了优化空间复杂度,我们可以注意到在填充 dp 表时,只需要用到当前行和上一行的数据。因此,可以只使用一个一维数组 dp 来代替二维数组,这样可以将空间复杂度从 O(m × n) 优化到 O(n)。
优化思路:
- 使用一个长度为
n的一维数组dp,该数组会存储当前行的最小路径和。 - 遍历每一行时,更新
dp[j]表示当前格子(i, j)的最小路径和。 - 每次更新
dp[j]时,dp[j]是从左边dp[j-1]或者从上边dp[j]更新而来,因此只需要保存当前行的状态。
要实现原地动态规划(In-Place DP),我们可以直接在输入的 grid 上进行修改,而不再需要额外的 dp 数组。通过不断更新 grid 中的元素为到达该位置的最小路径和,我们就可以实现空间复杂度为 O(1) 的解法。
思路:
- 初始条件:
grid[0][0]就是起点的值,不需要修改。 - 第一行只能从左边移动过来,所以
grid[0][j] = grid[0][j-1] + grid[0][j]。 - 第一列只能从上边移动过来,所以
grid[i][0] = grid[i-1][0] + grid[i][0]。 - 对于其他位置
grid[i][j],可以从上边或者左边移动过来,取两者中的最小值再加上当前格子的值:grid[i][j] = min(grid[i-1][j], grid[i][j-1]) + grid[i][j]。 - 最终的答案将保存在
grid[m-1][n-1],即右下角的位置。
代码实现
1 | class Solution: |
优化后:
1 | class Solution: |
原地dp:
1 | class Solution: |
复杂度分析
时间复杂度:$O(m×n)$
空间复杂度:$O(m×n)$ 到 $O(n)$ 到 $O(1)$。
5. Longest Palindromic Substring
题目描述
Given a string s, return the longest palindromic substring in s.
Example 1:
1 | Input: s = "babad" |
Example 2:
1 | Input: s = "cbbd" |
Constraints:
1 <= s.length <= 1000sconsist of only digits and English letters.
解题方法
动态规划
使用 动态规划 方法来求解最长回文子串问题。动态规划的核心思想是通过缓存子问题的结果,减少重复计算,从而提高效率。
动态规划解法思路:
定义状态:
- 用二维数组
dp,其中dp[i][j]表示子串s[i:j+1]是否是回文串。
- 用二维数组
状态转移:
- 初始化:所有长度为 1 的子串都是回文串,
dp[i][i] = True。 - 如果
s[i] == s[j]且dp[i+1][j-1] == True,则dp[i][j] = True,即s[i:j+1]是回文串。 - 否则,
dp[i][j] = False。
- 初始化:所有长度为 1 的子串都是回文串,
计算过程:
- 遍历所有可能的子串长度,从小到大计算每个子串是否是回文。
- 如果
dp[i][j]为True,则更新当前最长回文子串。
中心扩展法
可以通过动态规划或中心扩展法来解决这个问题。这里我们使用 中心扩展法,它的时间复杂度为 $O(n^2)$,适用于给定字符串的长度不超过 1000 的情况。
中心扩展法思路:
中心扩展法:一个回文串可以通过其中心进行扩展。对于每一个字符位置(或两个字符之间的位置),我们尝试扩展出一个回文串,并记录下最长的回文串。
- 每个字符可以作为回文的中心,有两种情况:
- 以一个字符为中心(奇数长度回文)。
- 以两个字符为中心(偶数长度回文)。
- 每个字符可以作为回文的中心,有两种情况:
步骤:
- 对每个字符(或者字符对)进行扩展,查找它们作为回文中心时的最长回文。
- 记录并返回最长的回文串。
代码实现
动态规划
1 | class Solution: |
中心扩展法
1 | class Solution: |
复杂度分析
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 动态规划 | $O(n^2)$,其中 $n$ 是字符串的长度。我们遍历每个子串并进行状态转移。 | $O(n^2)$,因为我们使用了一个二维数组 $dp$ 来记录所有子串的回文状态。 |
| 中心扩展法 | $O(n^2)$,其中 $n$ 是字符串的长度。对于每个字符,我们扩展回文的过程中最多需要 $O(n)$ 次操作。 | $O(1)$,因为只使用了常数的额外空间。 |
1143. Longest Common Subsequence
题目描述
Given two strings text1 and text2, return the length of their longest common subsequence . If there is no common subsequence , return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
- For example,
"ace"is a subsequence of"abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
1 | Input: text1 = "abcde", text2 = "ace" |
Example 2:
1 | Input: text1 = "abc", text2 = "abc" |
Example 3:
1 | Input: text1 = "abc", text2 = "def" |
Constraints:
1 <= text1.length, text2.length <= 1000text1andtext2consist of only lowercase English characters.
解题方法
这个问题是典型的动态规划问题,可以通过建立一个二维数组 dp 来解决。dp[i][j] 表示文本 text1 的前 i 个字符和文本 text2 的前 j 个字符的最长公共子序列的长度。
解题思路:
状态定义:
dp[i][j]表示text1[0..i-1]和text2[0..j-1]的最长公共子序列的长度。
状态转移:
- 如果
text1[i-1] == text2[j-1],那么dp[i][j] = dp[i-1][j-1] + 1,即如果当前字符相等,那么最长公共子序列的长度是前面两个字符串的最长公共子序列加上当前的字符。 - 如果
text1[i-1] != text2[j-1],那么dp[i][j] = max(dp[i-1][j], dp[i][j-1]),即最长公共子序列要么来自text1[0..i-2]和text2[0..j-1],要么来自text1[0..i-1]和text2[0..j-2],取二者中的最大值。
- 如果
初始化:
dp[0][j] = 0,表示text1为空时,任何text2的子序列都没有公共部分。dp[i][0] = 0,表示text2为空时,任何text1的子序列都没有公共部分。
最终答案:
- 最终的答案是
dp[len(text1)][len(text2)],即两个字符串的最长公共子序列的长度。
- 最终的答案是
代码实现
1 | class Solution: |
复杂度分析
时间复杂度: $O(m × n)$,其中 $m$ 和 $n$ 分别是 text1 和 text2 的长度。
空间复杂度: $O(m × n)$,用于存储 dp 数组。
72. Edit Distance
题目描述
Given two strings word1 and word2, return the minimum number of operations required to convert word1 to word2.
You have the following three operations permitted on a word:
- Insert a character
- Delete a character
- Replace a character
Example 1:
1 | Input: word1 = "horse", word2 = "ros" |
Example 2:
1 | Input: word1 = "intention", word2 = "execution" |
Constraints:
0 <= word1.length, word2.length <= 500word1andword2consist of lowercase English letters.
解题方法
要解决这个问题,我们可以使用动态规划。这是一个经典的编辑距离(Edit Distance)问题,常用的算法是Levenshtein Distance。我们可以通过动态规划计算将 word1 转换为 word2 所需的最少操作次数。
动态规划思路:
定义 dp[i][j] 表示将 word1[0..i-1] 转换为 word2[0..j-1] 所需的最少操作数。基本的转移方程如下:
- 如果
word1[i-1] == word2[j-1],则无需操作,dp[i][j] = dp[i-1][j-1]。 - 如果
word1[i-1] != word2[j-1],则需要通过以下三种操作之一进行转换:- 插入操作:将
word2[j-1]插入到word1[0..i-1]中,因此dp[i][j] = dp[i][j-1] + 1。 - 删除操作:删除
word1[i-1],因此dp[i][j] = dp[i-1][j] + 1。 - 替换操作:将
word1[i-1]替换为word2[j-1],因此dp[i][j] = dp[i-1][j-1] + 1。
初始条件:
- 插入操作:将
dp[0][j] = j,即将空字符串转换为word2[0..j-1],需要j次插入操作。dp[i][0] = i,即将word1[0..i-1]转换为空字符串,需i次删除操作。
我们注意到在填充动态规划表格时,每次只需要当前行和前一行的值。因此,我们可以通过只保留两行 dp 数组来减少空间复杂度,从 O(m * n) 优化到 O(n),其中 n 是 word2 的长度。
优化思路:
在计算 dp[i][j] 时,只依赖于 dp[i-1][j]、dp[i][j-1] 和 dp[i-1][j-1]。因此,我们可以使用两个一维数组:
prev:表示上一行的状态,即dp[i-1][j]。curr:表示当前行的状态,即dp[i][j]。
每次处理完一行后,将curr赋值给prev,并重新初始化curr,这样只用两个长度为n+1的数组即可完成计算。
代码实现
1 | class Solution: |
解释:
dp[i][j]存储从word1的前i个字符转换为word2的前j个字符所需的最小操作数。- 最终的结果就是
dp[m][n],其中m和n分别是word1和word2的长度。
优化后:
1 | class Solution: |
复杂度分析
时间复杂度:$O(m * n)$,其中 m 和 n 分别是 word1 和 word2 的长度。
空间复杂度:$O(m * n)$,因为需要一个大小为 (m+1) x (n+1) 的 dp 数组。优化后为 $O(n)$,因为我们只用到了两个长度为 n+1 的数组。