
前言
题单LeetCode 热题 100的图论部分,给出解析。
200. Number of Islands
题目描述
Given an m x n 2D binary grid grid which represents a map of '1's (land) and '0's (water), return the number of islands.
An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example 1:
1 | Input: grid = [ |
Example 2:
1 | Input: grid = [ |
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]is'0'or'1'.
解题方法
这个问题要求我们计算二维二进制网格中“岛屿”的数量。岛屿是由相连的陆地('1')组成的区域,并且被水('0')包围。相邻的陆地可以通过上下左右方向连接在一起。
解题思路:
- 遍历整个网格:
- 对于每一个格子,如果该格子是陆地(即
'1'),那么我们就找到一个新的岛屿。 - 发现新岛屿后,使用深度优先搜索(DFS)或广度优先搜索(BFS)将该岛屿的所有相连的陆地格子都标记为已访问过(可以将其值改为
'0'或其他值)。
- 对于每一个格子,如果该格子是陆地(即
- DFS/BFS 的作用:
- 从某个陆地格子出发,通过递归(DFS)或队列(BFS)将与其相连的所有陆地格子都访问并标记,这样我们就可以确定该岛屿的边界。
- 这样做之后,所有与该岛屿相连的格子就不会再被误认为是新的岛屿。
- 时间复杂度:
- 每个格子最多只会被访问一次,所以时间复杂度为 $O(m×n)$,其中 $m$ 是网格的行数,$n$ 是网格的列数。
代码实现
DFS 实现:
1 | class Solution: |
BFS 实现:
1 | class Solution: |
复杂度分析
时间复杂度:$O(m×n)$($m$ 与 $n$ 为行数与列数)
空间复杂度:$O(m×n)$
994. Rotting Oranges
题目描述
You are given an m x n grid where each cell can have one of three values:
0representing an empty cell,1representing a fresh orange, or2representing a rotten orange.
Every minute, any fresh orange that is 4-directionally adjacent to a rotten orange becomes rotten.
Return the minimum number of minutes that must elapse until no cell has a fresh orange. If this is impossible, return -1.
Example 1:
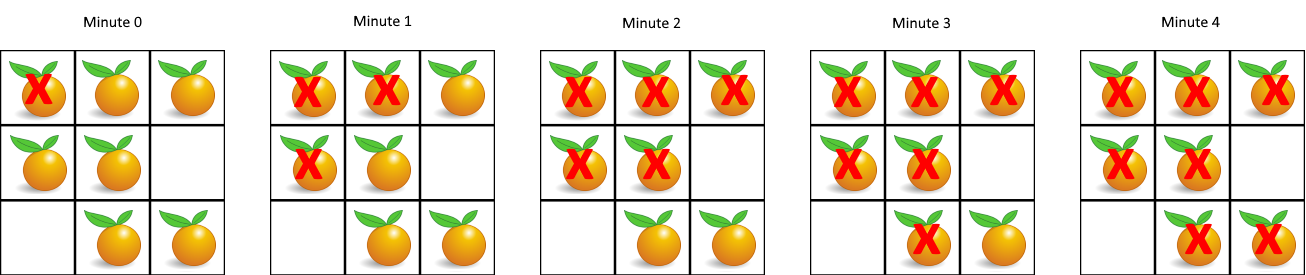
1 | Input: grid = [[2,1,1],[1,1,0],[0,1,1]] |
Example 2:
1 | Input: grid = [[2,1,1],[0,1,1],[1,0,1]] |
Example 3:
1 | Input: grid = [[0,2]] |
Constraints:
m == grid.lengthn == grid[i].length1 <= m, n <= 10grid[i][j]is0,1, or2.
解题方法
这道题的目标是模拟橙子腐烂的过程,腐烂的橙子会在每分钟四个方向(上下左右)传播给周围的新鲜橙子。如果最后所有的新鲜橙子都变成腐烂橙子,返回经过的最短分钟数;如果无法让所有新鲜橙子都腐烂,返回 -1。
这个问题可以使用广度优先搜索(BFS)来解决,把腐烂的橙子作为起始点,然后模拟它们向周围的四个方向传播,直到没有新鲜橙子为止。
解题思路:
初始化:
- 我们需要记录初始腐烂橙子的位置,作为BFS的起点。每次腐烂传播时,周围的相邻新鲜橙子会变成腐烂橙子。
- 如果最后还有新鲜橙子没腐烂,或者根本没有新鲜橙子,应该返回
-1。
BFS模拟:
- 遍历整个网格,找到所有腐烂橙子的位置,把它们放入队列中。每分钟,腐烂橙子会传播到其相邻的所有新鲜橙子。
- 用一个变量来记录经过的分钟数。
终止条件:
- 如果所有的腐烂橙子都传播完成,检查是否还有剩余的新鲜橙子。如果有,就返回
-1。 - 如果所有的新鲜橙子都腐烂了,返回经过的分钟数。
- 如果所有的腐烂橙子都传播完成,检查是否还有剩余的新鲜橙子。如果有,就返回
代码实现
1 | class Solution: |
复杂度分析
时间复杂度:$O(m×n)$,其中 $m$ 是行数,$n$ 是列数。我们最多遍历网格每个格子一次。
空间复杂度:$O(m×n)$,用于存储队列中腐烂橙子的数量,最多可能存储整个网格。
207. Course Schedule
题目描述
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course bi first if you want to take course ai.
- For example, the pair
[0, 1], indicates that to take course0you have to first take course1.
Return true if you can finish all courses. Otherwise, return false.
Example 1:
1 | Input: numCourses = 2, prerequisites = [[1,0]] |
Example 2:
1 | Input: numCourses = 2, prerequisites = [[1,0],[0,1]] |
Constraints:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCourses- All the pairs prerequisites[i] are unique .
解题方法
题目大意为:课程表上有一些课,有着修学分的先后顺序,必须在上完某些课的情况下才能上下一门,分析是否有方案修完所有的课程。
即题目需要判断这些课程是否能够构成有向无环图(DAG)
DFS
题目需要判断这些课程是否能够构成有向无环图(DAG),判断 DAG 使用拓扑排序。
采用 DFS 解答,思路如下:
解决思路:
- 图的表示:将课程和它们的依赖关系表示为一个邻接表。每个课程是一个节点,先修课程是有向边。
- 状态表示:
- **未访问 (0)**:课程尚未被访问。
- **访问中 (-1)**:课程正在当前的DFS路径中被访问(检测是否存在环的标志)。
- **已访问 (1)**:课程已经被访问,并且从该课程开始没有发现环。
- 环的检测:
- 使用DFS遍历每个课程。如果在DFS过程中遇到一个正在访问中的课程(状态为-1),则说明存在环,返回
false。 - 如果DFS成功完成没有发现环,则返回
true。
- 使用DFS遍历每个课程。如果在DFS过程中遇到一个正在访问中的课程(状态为-1),则说明存在环,返回
拓扑排序
同样的,可以使用拓扑排序来解决判断有向无环图的问题。
解决思路:
- 图的表示:同样使用邻接表表示课程和它们的依赖关系。
- 入度表示:每个课程的入度表示需要先修的课程数量。
- 拓扑排序:
- 初始化一个队列,将所有入度为0的课程加入队列。
- 从队列中依次取出课程,并减少相应依赖它的课程的入度。如果某个课程的入度减少为0,则将其加入队列。
- 如果最终处理的课程数量等于
numCourses,则可以完成所有课程,否则说明存在环,无法完成所有课程。
代码实现
DFS
1 | class Solution: |
拓扑排序
1 | from collections import deque |
复杂度分析
两个方法的复杂度是一样的。
时间复杂度:$O(V+E)$
空间复杂度:$O(V+E)$
208. Implement Trie (Prefix Tree)
题目描述
A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
Trie()Initializes the trie object.void insert(String word)Inserts the stringwordinto the trie.boolean search(String word)Returnstrueif the stringwordis in the trie (i.e., was inserted before), andfalseotherwise.boolean startsWith(String prefix)Returnstrueif there is a previously inserted stringwordthat has the prefixprefix, andfalseotherwise.
Example 1:
1 | Input |
Constraints:
1 <= word.length, prefix.length <= 2000wordandprefixconsist only of lowercase English letters.- At most
3 * 10^4calls in total will be made toinsert,search, andstartsWith.
解题方法
要实现 Trie 类,可以使用一种常见的方法——使用字典来模拟树的节点,每个节点存储字母以及一个标志,表示是否为某个单词的结尾。
代码实现
1 | class TrieNode: |
复杂度分析
无